
Dans cette nouvelle Question Technique, nous allons voir ce qui différencie principalement les architectures de processeurs ARM et x86.
Pendant des années, l’écrasante majorité des utilisateurs de produits informatiques grand public n’avaient affaire qu’à une seule famille de processeurs : les processeurs x86, produits principalement par Intel et AMD. Toutefois, avec l’avènement des appareils mobiles, les lignes ont bougé et c’est une autre famille qui a largement pris les devants en nombre d’appareils vendus : les processeurs ARM. Mais savez-vous quelles sont les différences fondamentales entre les architectures ARM et x86 ?
CISC vs RISC
La principale différence entre les deux architectures tient dans les choix de conception de leur jeu d’instruction : le x86 est une architecture CISC (Complex Instruction Set Computer), tandis que l’ARM est une architecture RISC (Reduced ISC).
Cela signifie que les puces ARM ne supportent que des instructions simples et de taille fixe (4 octets pour le jeu d’instructions ARM standard, 2 octets pour le jeu réduit Thumb), s’exécutant en un nombre constant de cycles, à l’inverse des puces x86 qui proposent des instructions nécessitant plus de cycles que d’autres, pour réaliser certaines tâches complexes. Les puces ARM supportent également moins de modes d’adressage (la façon de référencer une donnée dans une instruction), la plupart des instructions ne pouvant travailler qu’avec des données présentes dans un registre (des petites zones de mémoire intégrées au processeur), alors que la majorité des instructions x86 peuvent aller chercher des données directement en mémoire.
L’intérêt d’une architecture RISC se situe principalement dans la moindre complexité du schéma électronique de la puce : pour atteindre un même niveau de performances, il faut généralement moins de transistors, ce qui permet de réduire les coûts de production et d’avoir une meilleure efficacité thermique. Du fait de l’obligation de faire des accès mémoire explicites dans le code, les processeurs RISC sont également souvent dotés d’un plus grand nombre de registres, ce qui permet de réduire la fréquence des accès mémoire. Ainsi, l’architecture ARMv7 dispose de 15 registres principaux et l’architecture ARMv8 en comporte 31, alors que le x86 n’en possède que 8 pour le code 16/32/64 bits et 8 supplémentaires réservés au code 64 bits.
Les architectures CISC ont pour leur part l’avantage de permettre un code exécutable plus compact, réduisant ainsi le nombre d’accès à la mémoire. Par ailleurs, même si elles sont plus longues à exécuter que les instructions simples, certaines instructions spécialisées peuvent s’exécuter bien plus vite que leur équivalent en instructions simples. En contrepartie, l’étage de décodage des instructions est plus complexe, puisqu’il doit être capable d’interpréter un grand nombre d’instructions, de tailles très variables (les plus courtes ne font qu’un seul octet, mais les plus longues frisent les 20 octets) et de gérer des modes d’adressage avancés, nécessitant de réaliser des opérations arithmétiques pour déterminer les adresses. Par exemple, l’un des modes d’adressage du x86 permet d’utiliser des adresses de la forme R1+R2*C1+C2 ou R1 et R2 sont le contenu de deux registres et C1 et C2 deux constantes intégrées directement dans le code de l’instruction.
Notons toutefois qu’en pratique les processeurs x86 d’aujourd’hui ont en fait un cœur d’exécution interne plus proche d’une architecture RISC que d’une architecture CISC, associé à un étage de décodage des instructions qui s’occupe de convertir le flux d’instructions x86 en instructions internes plus simples. Ces processeurs restent des processeurs CISC, du fait de leur interface interne, mais le recours à une architecture interne RISC permet de réduire la complexité des unités d’exécution.
À l’inverse, les processeurs ARM (et bon nombre d’autres processeurs RISC) ont adopté des instructions spécialisées, notamment pour les traitements multimédia, via des extensions du jeu d’instructions de base, comme par exemple l’extension NEON.
Optimisation logicielle et optimisation matérielle
Le choix entre RISC et CISC a une incidence directe sur la façon d’optimiser les performances du système.
Dans le monde ARM, c’est avant tout sur le logiciel que le travail d’optimisation doit être fait, et en particulier sur le compilateur. En effet, les instructions s’exécutant à peu près toutes dans un même nombre de cycles, il est essentiel de produire du code utilisant le moins d’instructions possible : pour un même résultat final, plus le code sera court, plus il sera rapide.
Dans le monde x86, il est bien évidemment aussi important de réaliser des optimisations au niveau logiciel, mais elles ne portent cette fois plus simplement sur le nombre d’instructions (pour un même résultat, un programme de 27 instructions peut être plus performant qu’un autre de 23 instructions…), mais aussi sur le choix des instructions complexes et des modes d’adressage, qui peuvent parfois avoir un impact très important sur les performances.
En plus de cette optimisation logicielle, il y a aussi un gros travail d’optimisation fait par le CPU lui-même. Une instruction de longue durée pouvant bloquer les instructions suivantes dans l’attente de son résultat, les fondeurs ont développé des systèmes de plus en plus complexes pour limiter la casse dans ces situations. Ainsi, les processeurs se sont mis à anticiper le résultat pour traiter les instructions suivantes (prédiction de branchement), quitte à recommencer si le résultat définitif n’était pas celui attendu, à exécuter les instructions dans le désordre (out-of-order), et même à regrouper plusieurs instructions en une seule. Tous ces traitements ont bien sûr un coût en transistors, mais en contrepartie elles peuvent parfois apporter des gains importants d’une génération à l’autre de processeur sans que les logiciels aient besoin d’être adaptés.
Le fait d’avoir des instructions de durée d’exécution variable peut également permettre de faire des optimisations à ce niveau, en réduisant le nombre de cycles nécessaires pour une instruction très utilisée. Par exemple, alors que le Pentium 4 avait besoin de 80 cycles pour effectuer une division entière à partir de deux registres, le Core 2 Duo n’avait plus besoin que de 17 cycles pour la même opération. À l’inverse, certaines instructions peuvent nécessiter plus de cycles sur une nouvelle génération, par exemple si elles sont peu utilisées et que le fondeur a décidé de sacrifier un peu les performances sur cette instruction au profit d’une réduction de la complexité ou de la consommation. Par exemple, une conversion de little-endian à big-endian sur le contenu d’un registre nécessitait 1 cycle sur le Pentium 4 contre 4 sur le Core 2 Duo.
Ces algorithmes toujours plus complexes intégrés au processeur sont en grande partie responsable de la consommation élevée des processeurs x86, mais c’est aussi grâce à cette complexité que les processeurs x86 haut de gamme restent aujourd’hui nettement plus performants que les meilleures puces ARM.
Mais ces derniers ont désormais eux aussi de plus en plus recours à ce type d’algorithmes pour améliorer les performances, quitte à augmenter un peu la consommation. Par exemple, depuis le Cortex-A9, les Cortex haut de gamme (A9, A15, A57…) disposent eux aussi d’un pipeline out-of-order de plus en plus poussé, tandis que les déclinaisons d’entrée de gamme qui visent avant tout la faible consommation (A5, A7, A53) conservent un pipeline in-order.
Au final, malgré des philosophies initiales très différentes, les puces ARM et x86 sont donc de plus en plus proches techniquement : les puces ARM haut de gamme se complexifient pour gagner en performances, atteignant désormais les performances de l’entrée de gamme x86, pendant que les puces x86 d’entrée de gamme se simplifient pour gagner en consommation, au point que les plus petits cœurs x86 d’aujourd’hui commencent à approcher la taille des gros cœurs ARM. Par exemple, avec une même finesse de gravure de 28 nm, un cœur AMD Jaguar occupe 3.1mm² contre 1.62mm² pour un ARM Cortex-A15 offrant des performances du même ordre. Un cœur Haswell gravé en 28 nm occuperait pour sa part une surface de l’ordre de 23mm², mais avec des performances sans commune mesure avec celles d’un Cortex-A15.

La stratégie commerciale
Une fois n’est pas coutume, La Question Technique va aborder l’aspect commercial… Impossible en effet de comparer x86 et ARM sans évoquer les stratégies commerciales radicalement différentes. En effet, si l’excellente efficacité thermique des puces ARM et leur faible coût de production a joué un rôle majeur dans leur succès sur le secteur mobile, la politique commerciale d’ARM a forcément joué un rôle important également.
La société ARM a en effet fait le choix de ne pas fabriquer de processeurs. Elle se contente de concevoir des architectures (ARMv6, ARMv7, ARMv8…) et diverses microarchitectures de référence implémentant ces architectures (les fameux Cortex), puis vend des licences sur ces architectures. Les fabricants des puces ARM peuvent alors soit prendre une licence sur l’architecture et concevoir leur propre microarchitecture, comme le font par exemple Apple et Qualcomm (et bientôt, nVidia, Samsung…), soit prendre une licence sur une microarchitecture de référence et l’intégrer avec d’autres circuits pour former un SoC complet. Pour ce faire, ils peuvent d’ailleurs également prendre des licences sur d’autres circuits conçus par ARM, notamment les GPU Mali.
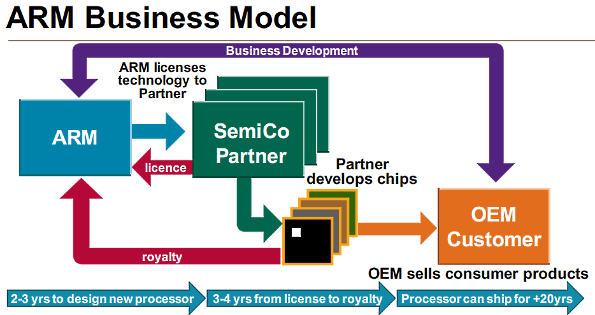
Cette stratégie rend le monde ARM très ouvert et concurrentiel, avec plusieurs dizaines de fabricants de puces ARM, et offre la possibilité de réaliser assez simplement des processeurs et des SoC répondant à des besoins spécifiques, ce qui a été un gros plus avec l’arrivée des smartphones, pour lesquels il a été nécessaire de disposer de puces embarquant des GPU performants, quasi inexistantes auparavant. Aujourd’hui, ARM propose un portefeuille de 1000 licences, utilisées par plus de 300 sociétés tierces (en croissance de plusieurs dizaines par an) dont la moitié environ commercialise actuellement des puces ARM, avec à la clé un chiffre impressionnant : la production de puces ARM atteint 10 milliards d’unités par an !
Dans le monde x86, la conception de l’architecture est principalement effectuée par Intel, avec quelques emprunts à AMD, en vertu d’accords de licence croisés conclus entre les deux fondeurs. Mais par contre, les licences sur l’architecture sont bien plus limitées. En effet, comme Intel produit ses propres processeurs, tout fondeur titulaire d’une licence x86 devient un concurrent d’Intel. Ainsi, aujourd’hui seuls deux fondeurs produisent encore des CPU x86 sous licence : AMD et VIA, qui a récupéré la licence de Cyrix en le rachetant.
Par ailleurs, ces licences se limitent à l’architecture. Intel conçoit bien des microarchitectures, mais elles sont exclusivement réservées à sa propre production. Les fondeurs qui souhaitent produire des puces x86 doivent donc concevoir leurs propres microarchitecture, ce qui est loin d’être simple face à la force de frappe dont dispose Intel, d’autant plus qu’Intel s’occupe à la fois de la conception de ses puces et de leur production, ce qui lui permet d’adapter au mieux ses puces à ses processus de production (et inversement) et de réaliser des marges importantes, du fait de l’absence d’intermédiaire, ce qui offre ensuite à la R&D des budgets importants… Intel fait ainsi en moyenne entre 15 et 20% de bénéfice net sur ses processeurs, alors que les royalties touchés par ARM sur les puces produites par ses partenaires sont généralement compris entre 1 et 2%.
Mais avec l’avènement des SoC mobiles, Intel pourrait assouplir un peu sa stratégie de licences pour mieux répondre aux besoins du secteur mobile, comme le montre le récent accord conclu avec Rockchip. Spécialisé jusqu’à présent dans les SoC ARM d’entrée de gamme, le chinois va en effet se lancer dans la conception de SoC x86 qui auront la particularité d’utiliser une microarchitecture Intel Atom, et non pas simplement une architecture x86. Ils devraient également embarquer un modem Intel, tandis que Rockchip s’occupera de l’intégration des autres composants du SoC, en particulier le circuit graphique, qui ne sera pas d’origine Intel. Ces SoC resteront par contre vendus sous la marque Intel, même si leur fabrication sera confiée à un autre fondeur (probablement TSMC).
Excellent article ! Merci pour toutes ces précisions. Continuez comme ça avec les LQT, c’est à chaque fois passionnant !
Merci pour cet excellent article !!!
« Cela signifie que les puces ARM ne supportent que des instructions simples »
Pour moi les instructions RISC ne sont pas forcément « plus simples », si on prend l’exemple de la transition de l’archi Motorola 68k CISC vers le Power PC RISC, les instructions ont plutôt eu tendance à devenir moins simples, beaucoup d’entre elles étant triadiques notamment…
La quasi totalité des instructions d’un proc CISC comme le x86 de base sont d’ailleurs déjà tellement simples qu’on ne peut pas les simplifier, on ne peut guère simplifier que les modes d’adressage…
Chez Motorola ils avaient un machin hybride aussi le Variable Length RISC, une archi RISC mais des opcodes de taille variable (coldfire…)
Oui, c’est une tendance, comme avec l’arrivée d’instructions spécialisées. Les RISC se complexifient pour plus de performances, les CISC se simplifient pour moins de consommation.
Mais ça reste quand même globalement des instructions relativement simples. La contrainte de la constance de la durée de traitement d’instruction limite forcément à ce niveau (cela dit, je ne sais pas si c’est encore systématiquement respecté pour toutes les instructions).
Et la complexité ne vient pas forcément du nombre d’opérandes… Une opération à trois opérandes comme le ADC de l’ARM (Addition de deux entiers + retenue, soit trois opérandes), ça reste une instruction très simple. On est loin par exemple de la complexité du F2XM1 du x86 (enfin du x87, mais aujourd’hui c’est pareil ^^) qui ne prend qu’une seule opérande x et calcule 2^(x-1).
Typiquement, le F2XM1 c’est le genre d’instructions qu’on ne devrait pas trouver en RISC. En RISC, on ferra d’abord y=x-1, puis r=2^y (et pour ça, on utilisera pas une instruction « puissance de 2 », mais plutôt un shift). C’est aussi pour ça qu’il y a souvent plus de registres en RISC, on calcule plus souvent de façon explicite des résultats intermédiaires (idem pour les adressages complexes, comme il y en a pas ou très peu, on doit calculer explicitement les adresses).
Y a aussi le FYL2XP1 par exemple, qui fait y*log2(x+1). Là encore, en philosophie RISC, on s’emmerde pas avec une instruction comme ça. On fait z=x+1 puis a=log2(z) puis r=y*a.
Mais bon, comme dit dans l’article, la frontière entre RISC et CISC s’efface de plus en plus, donc je serais pas surpris de trouver quand même un équivalent du F2XM1 ou du FYL2XP1 dans un RISC, même si c’est pas du tout dans la philosophie du RISC.
En x86 ont as tendance a garder beaucoup trop de compatibilité avec les anciennes generations, ce qui as un cout énorme.
Abracadabra ! Quelques-un(e)s d’entre vous ont accès au livre des secrets dans lequel les mots transforment les mots… et la matière… en images, en sons, en calculs, en messages, en or, en plomb, en joie et en larmes ! Les autres regardent la magie opérer sous des couches de marketing et de vent, dans des tas de labyrinthes de folies de petits transistors bien dressés. Une tribu de mages au-delà des montagnes commence même à raconter la prophétie de la danse quantique dans les tunnels des réseaux de la fourmilière des circuits imprimés ! Est-ce que leurs prêtres seront assez convaincants pour qu’une nouvelle religion s’installent avec son architecture encore plus mystérieuse ? En attendant, est-ce que l’acquisition d’un « nordinateur », l’assemblage d’une configuration ne ressemble pas de plus en plus à de la prière ou au tirage d’une grande loterie du hasard ? Ben oui, depuis la fonderie des processeurs plus ou moins blindés de tolérance d’erreurs jusqu’à l’adéquation entre le matériel et le logiciel, l’optimisation finale et suprême ne doit être à la portée que d’une poignée d’initié(e)s respectueusement évoqué(e)s au début de cette réflexion un poil ironique.
De la part d’un partisan de la LQT qui continue pendant les vacances. (C’est vache, ça, hein, le rédac ?).
@LeuBleu> Je dirais qu’à part quelques entorses à l’orthographe qui ne peuvent être juste dues qu’à la licence poétique, c’est aussi profond que creux, à moins que ce ne soit le contraire.
Comprendre un sujet c’est le « con prendre », « prendre avec », partager finalement mais pas nécessairement dans le but de s’enrôler dans l’occultisme de je ne sais quelle secte diafoireuse.
Nous avons là encore un excellent résumé non exhaustif car il aurait aussi pu aborder la parenthèse IBM et ses Power ou les beautés cachées de l’Itanium ou de manière encore plus dévoyée de l’abandon de l’entretien des noyaux RISC de NT par Microsoft et de ses conséquences à l’heure actuelle.
Cette LQT mérite qu’on s’y arrête quoi qu’il arrive ne serait-ce que pour notre culture.
Bonnes vacances.
@LeuBleu> P.S. La première phrase de mon post parle de ta prose, pas de l’article bien sûr.
Ok, Prof, bien vu : un ou deux verbes conjugués à la truelle. Très bon pour l’orgueil d’avoir à reconnaître quelques failles. Pour donner dans le plus direct, en creux et bosses, le rappel des conditions de fabrication de nos petits processeurs avec leurs tests de tolérance qui les classent en degrés de qualité aux codes desquels le consommateur n’a pas vraiment accès ajouté (le rappel) à celui de bien marier matériel et logiciel pour taper la perf. n’aboutit qu’à une somme d’évidences :
– la machine idéale (polyvalente et tout et tout) n’existe pas,
– le bon compromis pour soi réclame des connaissances
autres que celles des catalogues et leur application,
– il restera quand même une part de hasard au moment
de l’assemblage en fonction des bons ou mauvais numéros
de série des composants tirés.
C’est tout. Réflexion dérisoire pour l’expert allaité au « livre des secrets » de l’informatique. Plume pour d’autres, nourris aux slogans publicitaires des constructeurs. Il n’y a pas plus de commentaire idéal pour cent pour cent de lecteurs que d’ordinateur polyvalent et champion toutes catégories.
Louée soit, en tout cas, la LQT et puisse-t-elle (« bis repetita… »)
nous envoyer sa petite carte postale de vacances,
si vacances il y a !
Sur les différences ARM, x86 il manque le traitement des niveaux de privilèges :
Ring 0 à 3 sur x86 (voire plus avec la virtualisation),
niveau privilégié ou normal sur ARM
Sur x86 on a aussi différents modes de fonctionnement (au delà des modes d’adressage) :
mode réel (pas de privilège, 1 Mio accessible en mémoire),
mode protégé (4 niveaux de Ring, 4 Gio accessible en 32 bits, segmentation, pagination),
mode virtuel x86 (une variante du mode réel),
mode SMM (un mode plutot obscur difficilement controlable depuis un OS);
Ce dernier n’étant pas le mieux documenté du lot (euphémisme)
Toujours aussi bons chez PCworld, merci !
On trouve des ARM + rapide que des Atom. Et on est à quelques jours des Cortex-A17. Mais Intel en voulant rattraper les ARM baisse, baisse et baisse encore les fréquences de ces entrée de gamme : dans la prochaine fournée qui sera en 14nm il y aura du i7 avec une fréquence de base à 0,8GHz. A cette même période devrait apparaître les Cortex-A57 à 2GHz avec qui il va être intéressant de comparer.
Gros doute quant à l’équivalence A15/Jaguar…
J’ai plus l’impression que la différence est du même ordre qu’entre Jaguar et Haswell, avec un A57 qui est lui un peu moins poussif.
J’ai regardé divers comparatifs, en gros un Jaguar 1.5 GHz fait rarement plus de 50% de mieux qu’un A15 1.7 ou 1.8 GHz. Donc pour moi c’est du même ordre.
Voir par exemple les tests sur browser là : http://www.notebookcheck.net/SoC-Shootout-x86-vs-ARM.99496.0.html
Le Jaguar 1.5 fait au mieux un +46% par rapport au Tegra 4 (A15 1.8 GHz), au pire un -12%.
Geekbench donne même l’avantage au A15… mais en même temps j’ai toujours considéré Geekbench comme non fiable ^^ (et Notebookcheck a l’air de mon avis là dessus, ça me rassure vu le nombre de gens qui ne jurent que par Geekbench ^^).
Après, c’est vrai que les tests browsers, c’est assez particulier, c’est pas toujours directement représentatif des performances brutes. Mais en même temps, c’est bien plus représentatif des usages sur le type d’appareils qui embarquent les SoC mobile : beaucoup de web et de bureautique, tandis que côté multimédia c’est surtout les circuits de décodage dédiés qui travaillent, pas les CPU.
Il est loin le temps ou un DEC Alpha ecrasait tout x86 sur son passage 🙂