Vous connaissez tous les CAPTCHA, ces systèmes destinés à vérifier que le client qui se connecte a un service distant est bien un humain et non un robot aux intentions pas toujours bienveillantes…
Ces tests fonctionnent le plus souvent en affichant des chiffres ou des lettres déformés, pour rendre leur lecture impossible avec un logiciel de reconnaissance de caractère (OCR) classique. Le service reCAPTCHA utilise d’ailleurs justement des mots non reconnus par un OCR, issus de livre scannés.
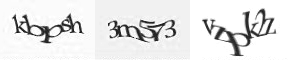
Au fil du temps, la plupart des systèmes de CAPTCHA ont renforcé leur complexité, généralement en déformant toujours plus les caractères, en réponse à des solutions d’OCR toujours plus performantes… Et ce qui devait arriver arriva…
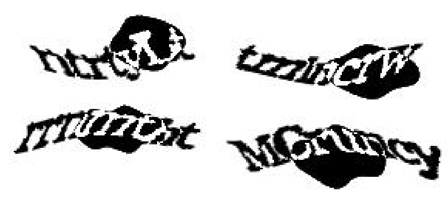
En effet, alors qu’aujourd’hui certains systèmes de CAPTCHA deviennent quasiment indéchiffrables pour un humain, les meilleurs algorithmes de reconnaissance savent pour leur part très bien le faire… Google a ainsi constaté que son algorithme de reconnaissance de caractère développé pour détecter les numéros de rue sur les photos de Google Street View est aussi redoutablement efficace pour résoudre les CAPTCHA : les problèmes les plus compliqués du service reCAPTCHA sont résolus avec un taux de réussite de 99%, supérieure à ce dont sont capables la plupart des humains…
Pour continuer à lutter efficacement contre les robots malveillants, les systèmes de CAPTCHA vont donc devoir évoluer, pour ne plus reposer simplement sur la reconnaissance de caractères tordus. Différents systèmes sont d’ores et déjà expérimentés (reconnaissance d’objets, compréhension de texte…), et il faudra espérer qu’ils seront déployés massivement avant que les OCR des robots arrivent au niveau de celui de Google (qui a sans doute une bonne longueur d’avance, étant donnés les moyens dont dispose Google), mais aussi qu’ils proposent des problèmes plus simples pour un humain que les mots totalement distordus proposés actuellement…